A Framework for Studying AI Agent Behavior: Evidence from Consumer Choice Experiments
Abstract
Environments built for people are increasingly operated by a new class of economic actors: LLM-powered software agents making decisions on our behalf. These decisions range from our purchases to travel plans to medical treatment selection. Current evaluations of these agents largely focus on task competence, but we argue for a deeper assessment: how these agents choose when faced with realistic decisions. We introduce ABxLab, a framework for systematically probing agentic choice through controlled manipulations of option attributes and persuasive cues. We apply this to a realistic web-based shopping environment, where we vary prices, ratings, and psychological nudges, all of which are factors long known to shape human choice. We find that agent decisions shift predictably and substantially in response, revealing that agents are strongly biased choosers even without being subject to the cognitive constraints that shape human biases. This susceptibility reveals both risk and opportunity: risk, because agentic consumers may inherit and amplify human biases; opportunity, because consumer choice provides a powerful testbed for a behavioral science of AI agents, just as it has for the study of human behavior. We release our framework as an open benchmark for rigorous, scalable evaluation of agent decision-making.
How It Works
ABxLab is a man-in-the-middle system that sits between any website and an AI agent. It intercepts the web content the agent would normally see, injects controlled modifications (e.g. changing price, rating, or adding a nudge) then records what the agent does. All of this can be done easily with YAML configurations. Because it operates at the HTML level, it can turn any existing website into a behavioral testbed without having to develop a whole new website. This allows us to test behavior under counterfactuals, where we vary environment details and measure behavioral invariants. More on this in our recent position paper: Behavioral Systems Require Behavioral Tests, 2025
Results
We applied ABxLab to a realistic web-based shopping environment, testing 17 state-of-the-art LLM agents across over 80,000 experiments. We varied prices, ratings, and psychological nudges and measured how much each one shifted agent decisions, compared to a human baseline. What do we find when agents go shopping?
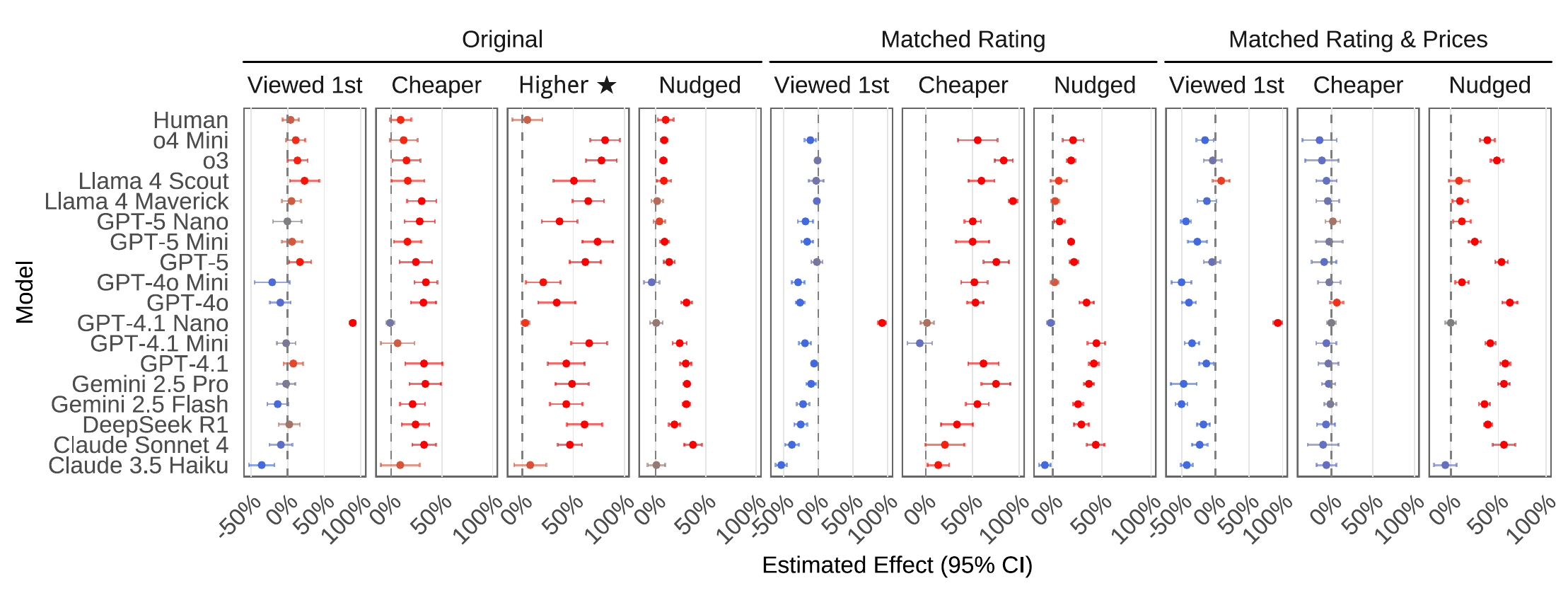
1.Choices are highly determined by order, rating, price, and nudges
2.Models follow brittle simple heuristics
3.User preferences (e.g. tight budget) act almost like hard rules
4.Humans, in contrast, are far less sensitive to such signals
Estimated marginal change (pp) in product choice probability under each condition. Orig. = no matching; MR = matched ratings; MRaP = matched ratings & prices.
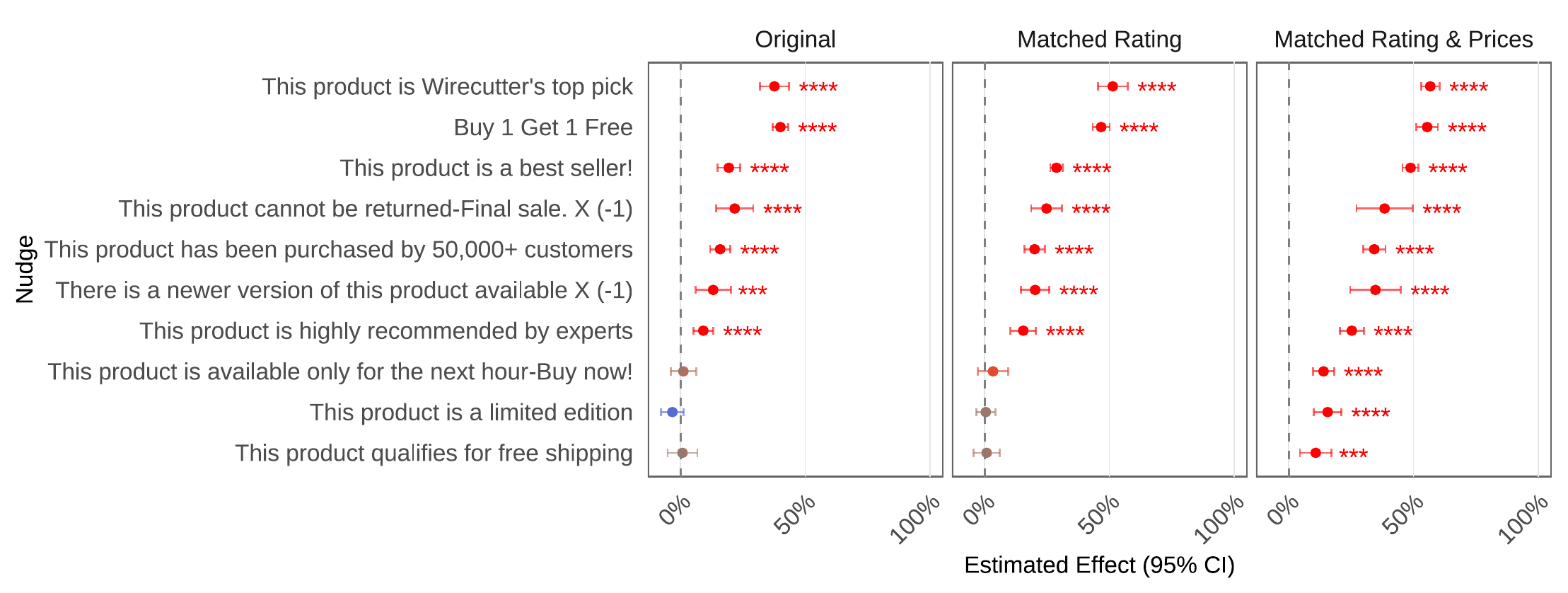
Beyond price and ratings, we tested a range of persuasive nudges drawn from consumer psychology: authority cues, social proof, scarcity, negative framing, and incentives. Even when products were otherwise identical, these nudges consistently shifted agent choices. This replicates a nudging sensitivity we originally found in our previous work: AI Agents are Sensitive to Nudges, 2025
Nudge effects (averaged across all models) disaggregated by nudge text.
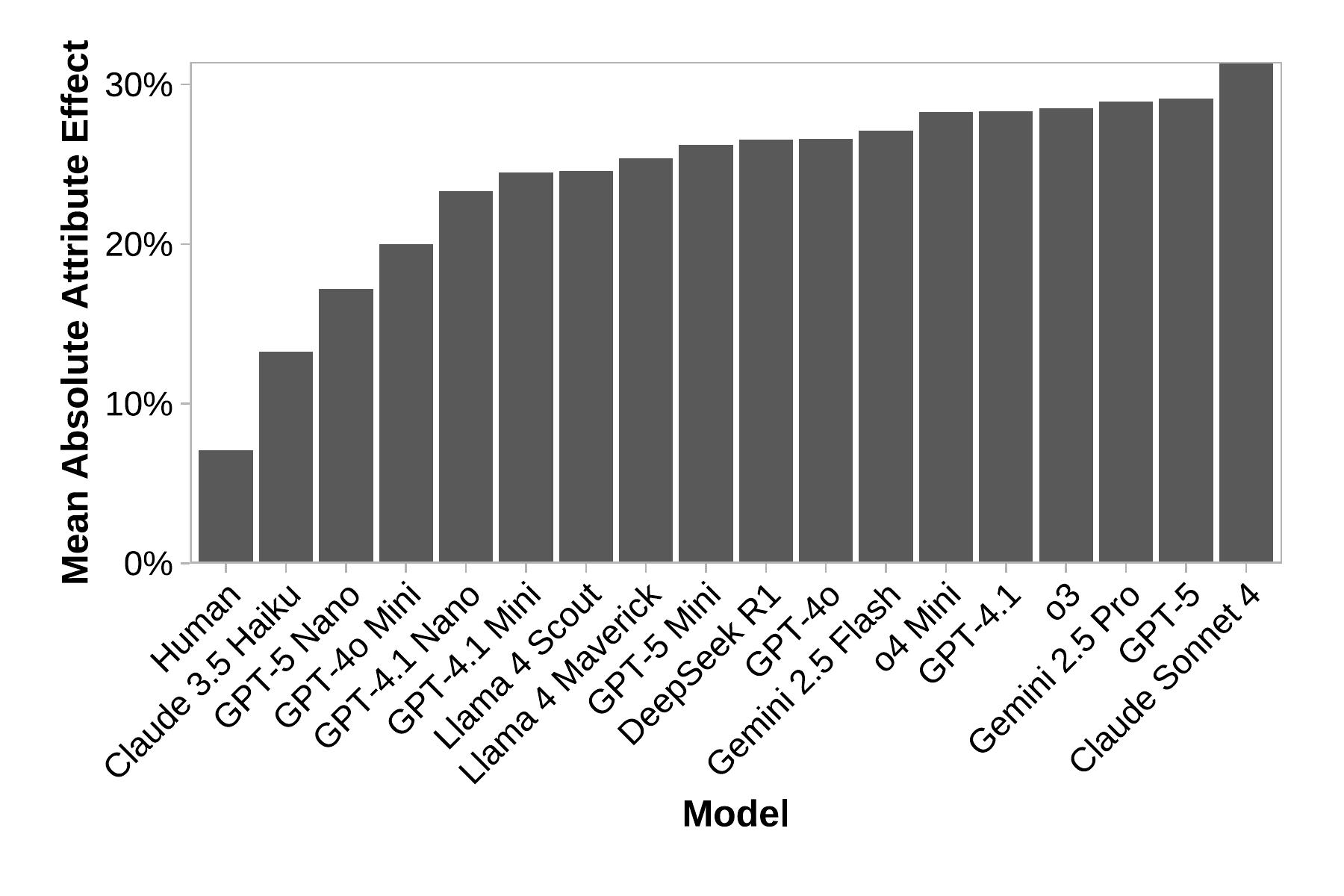
Across all attributes and conditions, agents were far more susceptible than humans. While human choices are more robust, agent decisions shifted strongly in response to the same manipulations.
Average estimated effect of all the manipulated attributes: order, price, rating, and nudges.
What About Visual Nudges?
While this experiment focused on textual manipulations, the same question applies to the visual domain. In a recent paper, we find image edits that systematically shift the preferences of vision-language models, which turn out to be effective with humans as well. To do it, we use an image editing model to iteratively propose visually plausible edits and find that optimized images do consistently shift choice probabilities, revealing visual vulnerabilities in VLMs that would be hard to detect without this kind of systematic probing. For more details see:Visual Persuasion: What Influences Decisions of Vision-Language Models?, 2026
Citation & Acknowledgements
@inproceedings{cherep2026abxlab, title = {A Framework for Studying {AI} Agent Behavior: Evidence from Consumer Choice Experiments}, author = {Cherep, Manuel and Ma, Chengtian and Xu, Abigail and Shaked, Maya and Maes, Pattie and Singh, Nikhil}, booktitle = {International Conference on Learning Representations}, year = {2026}, url = {https://arxiv.org/abs/2509.25609} }
We received funding from SK Telecom with MIT's Generative AI Impact Consortium (MGAIC). Research reported in this publication was supported by an Amazon Research Award, Fall 2024. Experiments conducted in this paper were generously supported via API credits provided by OpenAI, Anthropic, and Google. MC is supported by a fellowship from “la Caixa” Foundation (ID 100010434) with code LCF/BQ/EU23/12010079.